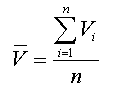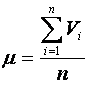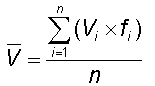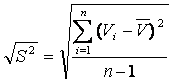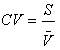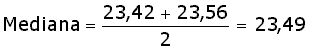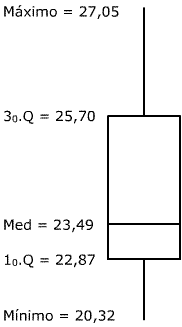|
Resumo
Neste módulo
foram trabalhadas algumas medidas descritivas básicas para análise
de uma base de dados não agrupados. Falamos da média, como
medida mais simples para representar esta base, desde que a mesma seja
suficientemente homogênea (ou seja, variabilidade suficientemente
pequena).
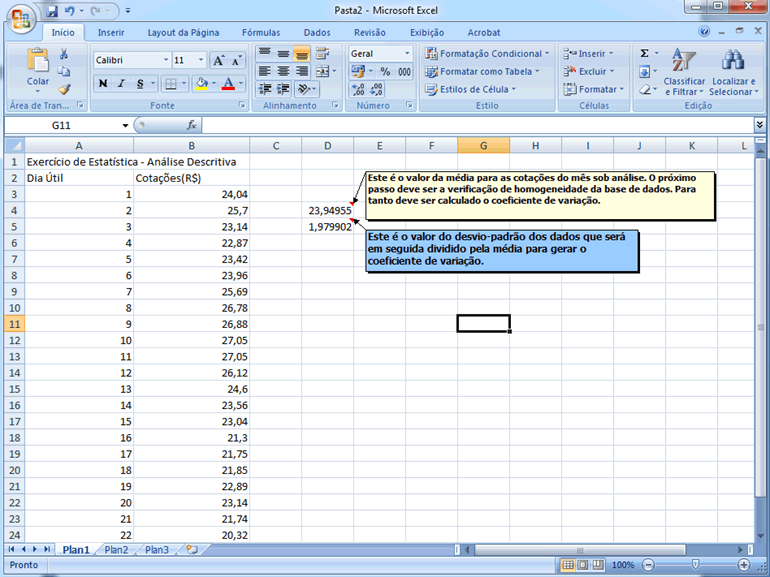
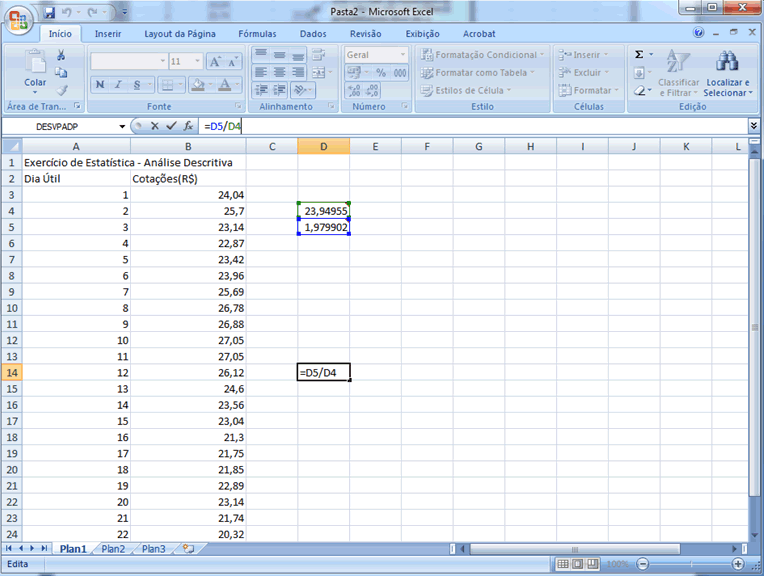
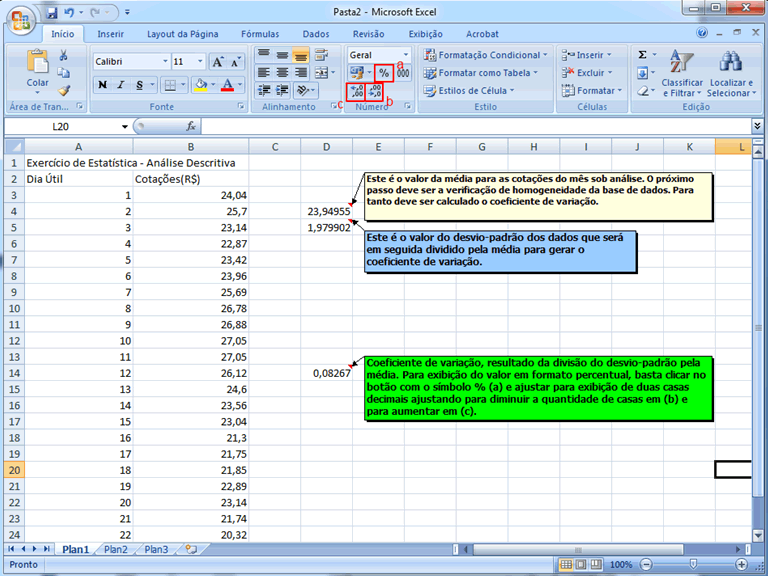
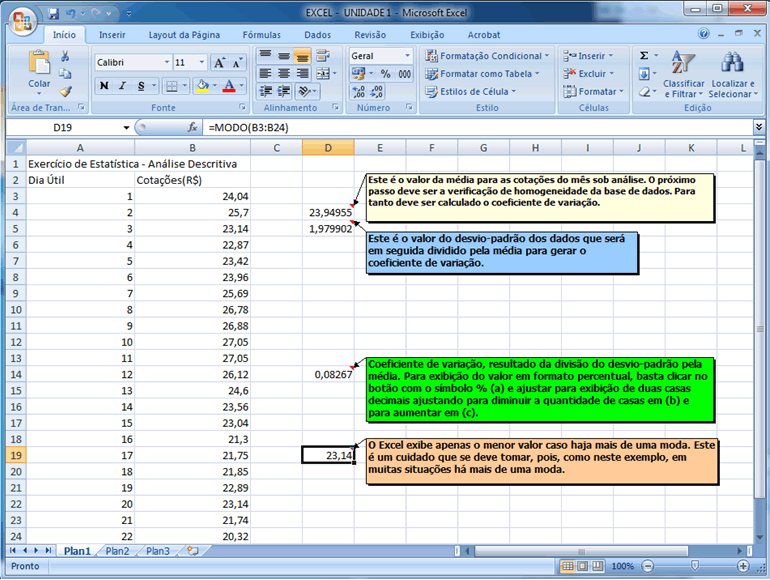
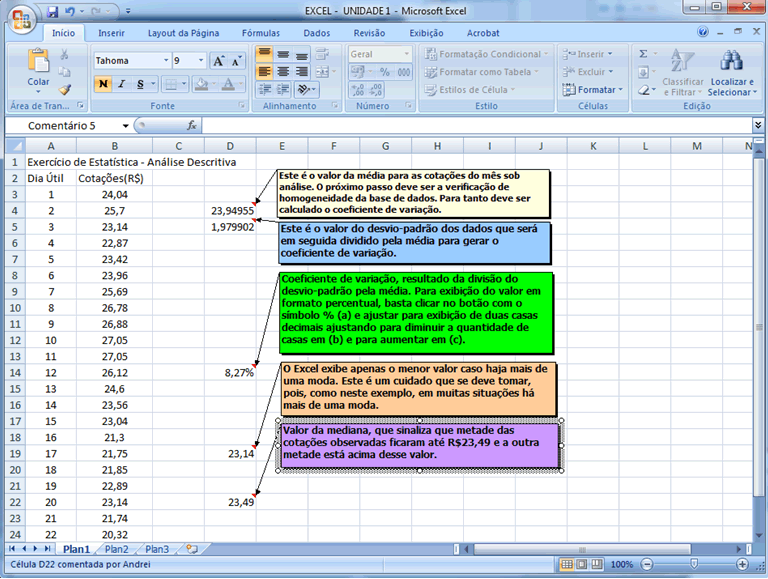
Esta avaliação
da homogeneidade/heterogeneidade será feita com base no coeficiente
de variação, que é uma expressão relativa
do desvio-padrão (comparativamente à média), sendo
então adimensional, apresentando de forma percentual a variabilidade.
Vimos que, neste caso,
foram estabelecidos intervalos que, empiricamente, têm sido utilizados
e aceitos como válidos para expressar a ordem de grandeza da dispersão
dos dados: até 15% (pequena); acima de 15% até 30% (média)
e acima de 30% (grande), devendo-se ter o cuidado de considerar o contexto
sob análise, que pode exigir um limite muito inferior a 15% para
admissão de homogeneidade dos dados (como muitas situações
de gestão da qualidade, por exemplo).
Surge então
a necessidade, tanto com bases de dados homogêneas, como com heterogêneas,
de diagnosticar a existência de pontos atípicos/discrepantes
(ou outliers), que são aqueles que "fogem" excessivamente
do perfil traçado pelo conjunto como um todo. Isto pode ser feito
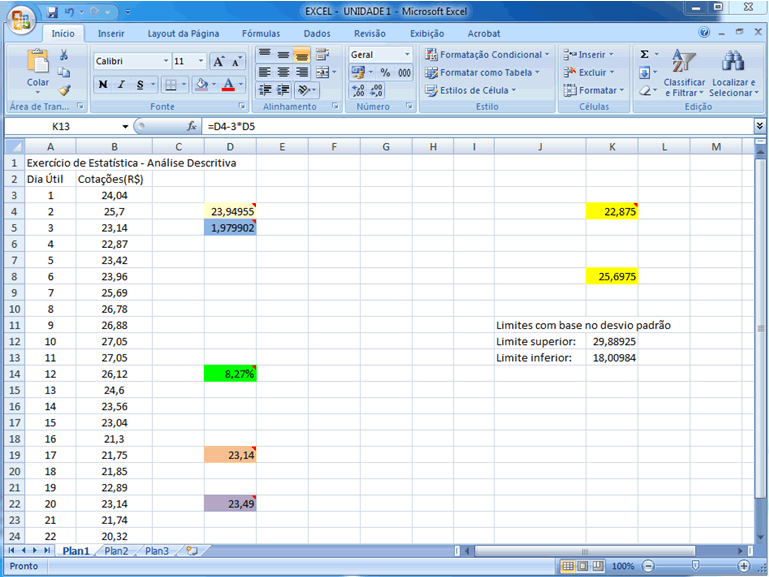
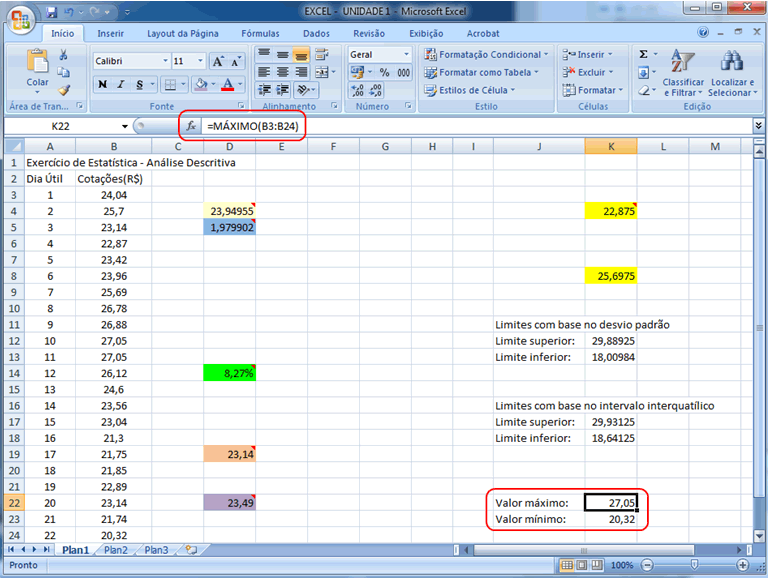
por duas abordagens: (1) estabelecer os limites máximos e mínimos
de "tolerância" a partir da média mais ou menos
três vezes o desvio-padrão, o que assegurará que este
intervalo contenha no mínimo 88,89% dos dados amostrais (desigualdade
de Tchebychev), sendo os restantes considerados pontos discrepantes; (2)
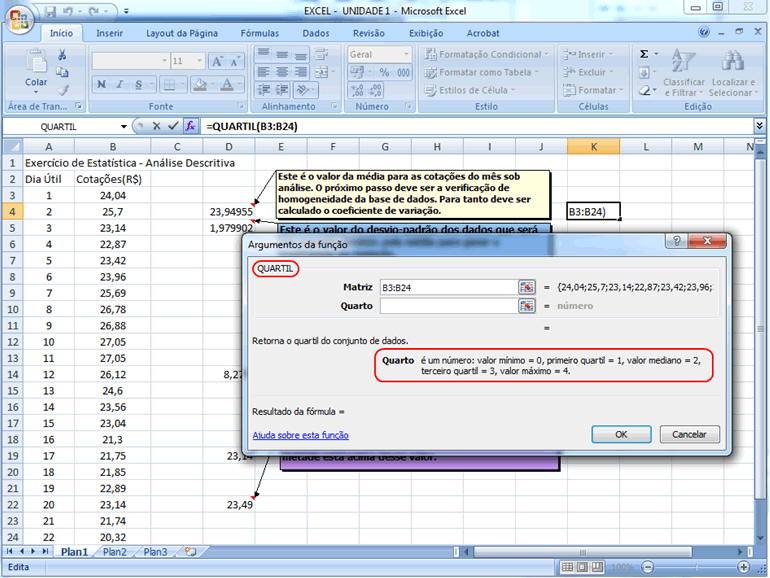
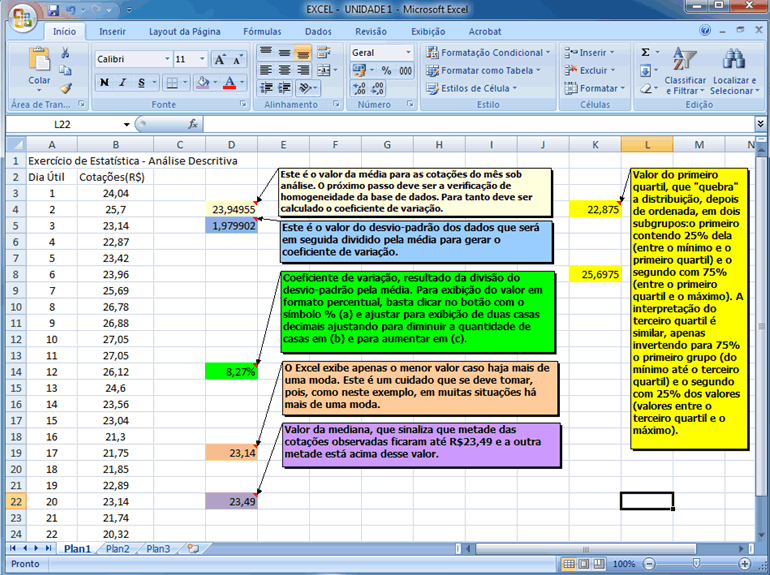
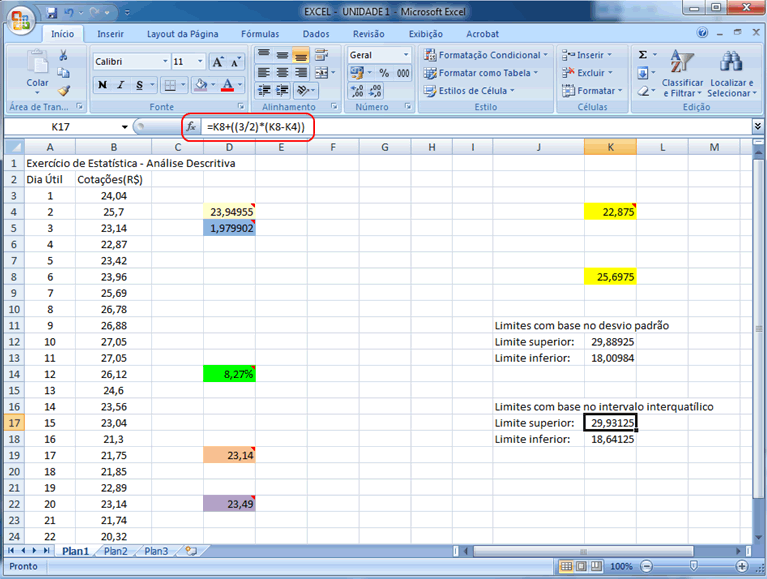
estabelecer estes limites partindo do primeiro e terceiro quartis, fazendo
então a diferença entre estes dois valores, multiplicando
esta diferença por 3/2, somando este resultado ao terceiro quartil
e subtraindo-o do primeiro quartil.
Feito isto e no caso
de bases de dados que não sejam consideradas suficientemente homogêneas,
deve-se partir para medidas complementares, uma vez que a média
não representa o conjunto analisado, nestas circunstâncias.
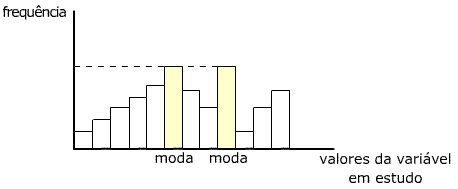
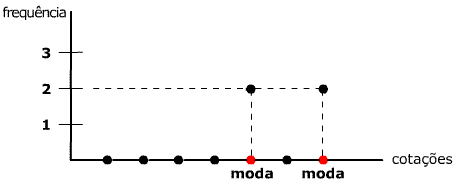
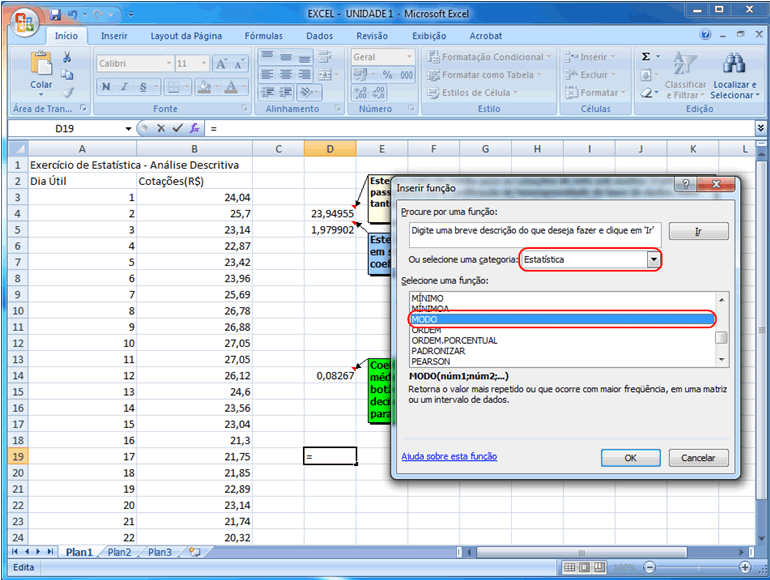
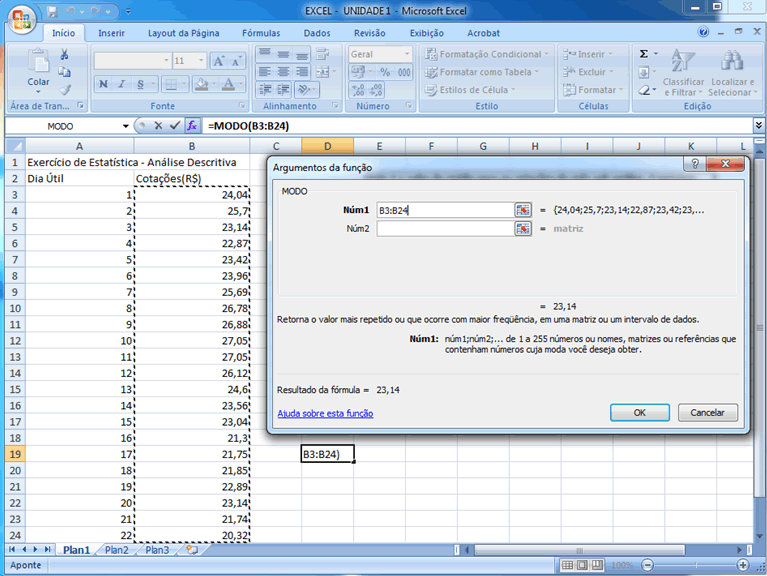
As medidas apresentadas foram moda, mediana e os próprios quartis
(além de citação dos decis e percentis). A moda é
o valor que mais aparece, aquele com maior incidência, o que pode
agregar valor à análise desde que represente uma quantidade
significativa de dados (uma moda que represente, por exemplo, dois por
cento do grupo pode não caracterizar aquele valor como um destaque
frente aos demais), considerando-se que a moda é única ou
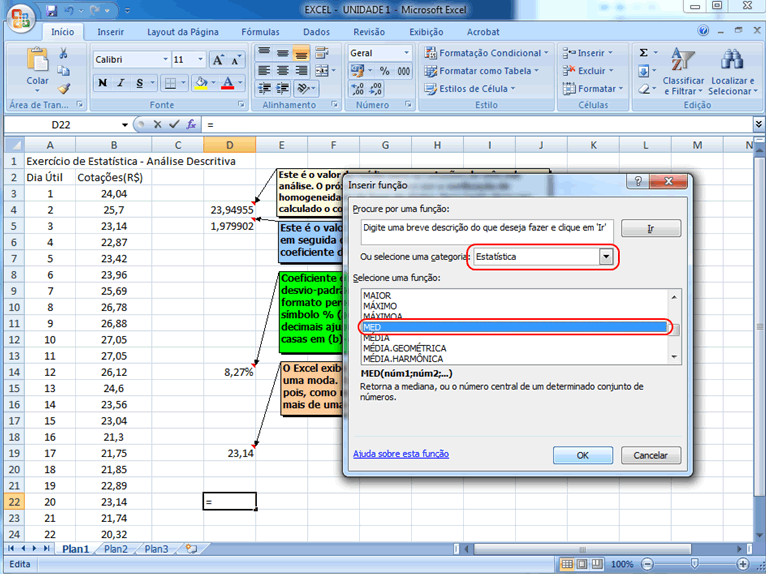
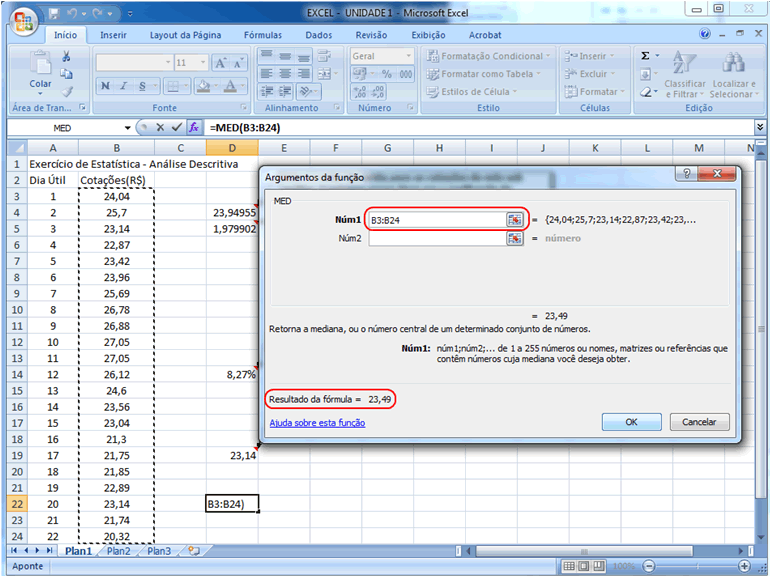
múltipla (ou mesmo se existe uma moda). A mediana divide o grupo,
já ordenado (de forma crescente ou decrescente), deixando metade
dos dados entre o valor mínimo e ela, mediana, e a outra metade
entre ela e o valor máximo observado. O objetivo da utilização
de valores que dividam a base de dados em grupos menores é visualizar
melhor o comportamento de sua distribuição, uma vez que
estes subgrupos devem ser mais homogêneos.
Foi também
apresentada uma proposta sintética, idealizada por Tukey, e subsequente
estrutura esquemática para suporte à análise descritiva.
Apresentam-se simultaneamente os valores mínimos e máximos
e os três quartis. O box-plot permite ter uma ideia a respeito
da distribuição, sendo que os pontos discrepantes também
são sinalizados no desenho.
|