Se os dados a serem analisados forem populacionais, isto é, todos os dados existentes, a variância (σ ²) será dada por:
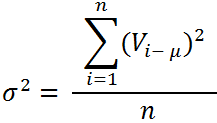
Perceba que, na formulação utilizada para a determinação da variância populacional, o denominador da expressão é dado apenas por "n", que indica o número de dados em análise. Já para uma base de dados amostrais, esse denominador será "n-1". Essa subtração de uma unidade no denominador da variância amostral está ligada à redução de um grau de liberdade (GL) que passamos a ter quando trabalhamos com esses dados.
Devemos lembrar que, na análise de dados amostrais, estamos, na verdade, tentando caracterizar informações de sua população de origem e a redução de uma unidade no denominador da expressão da variância faz com que, matematicamente, este valor fique um pouco maior, tentando garantir a explicação da dispersão total dos dados populacionais que deram origem à amostra que está sendo estudada.
Então, apenas para reforçar o conceito:
| Quando trabalhamos com todos os dados estaremos trabalhando com valores populacionais. Quando estivermos trabalhando apenas com uma amostra, ou seja, parte dos dados, estaremos trabalhando com valores amostrais. |
No exemplo das ações, como estamos trabalhando com apenas algumas ações então estamos trabalhando apenas com uma amostra, logo deveremos utilizar a fórmula dos dados amostrais (n-1). Caso a fizéssemos uma análise com todas as ações, então deveríamos utilizar as fórmulas populacionais, ok?
Outro exemplo: suponha
que você queira avaliar a média de altura dos alunos da sua
sala. Caso você meça todos os alunos da sala e use esses
dados para medir a média, então estará usando dados
populacionais. Caso você não tenha tempo, ou não tenha
como medir a altura de todos os alunos e meça apenas uma parte
dos alunos, então estará trabalhando com dados amostrais.
Fácil, não é?