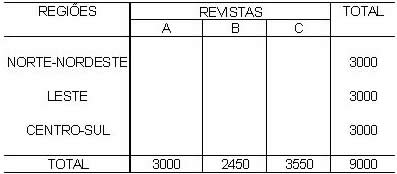
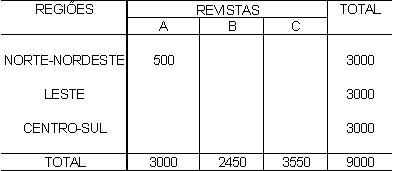
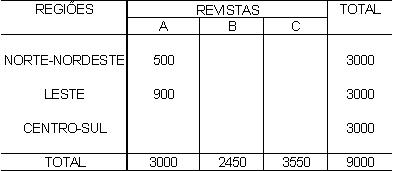
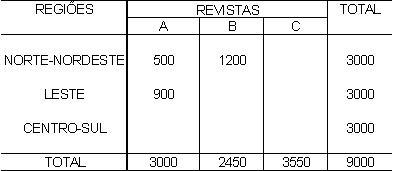
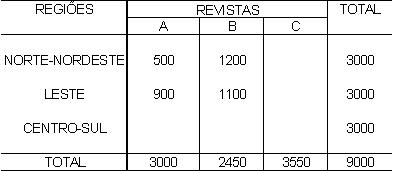
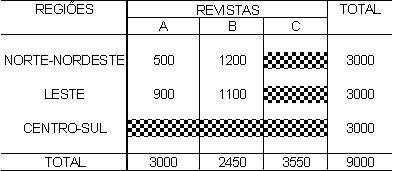
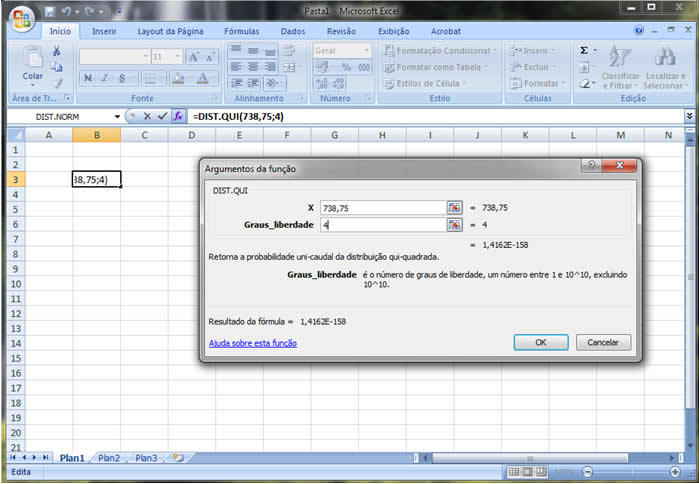
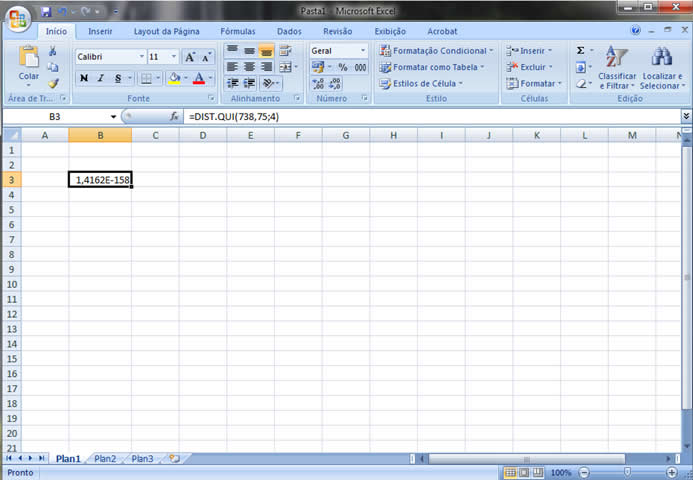
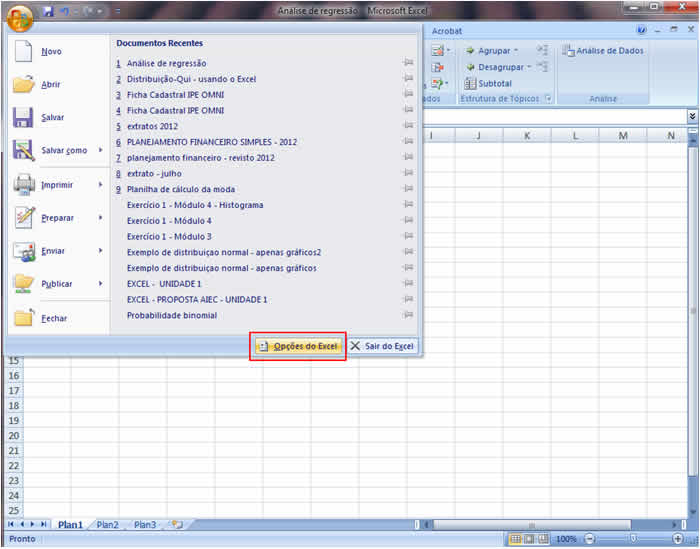
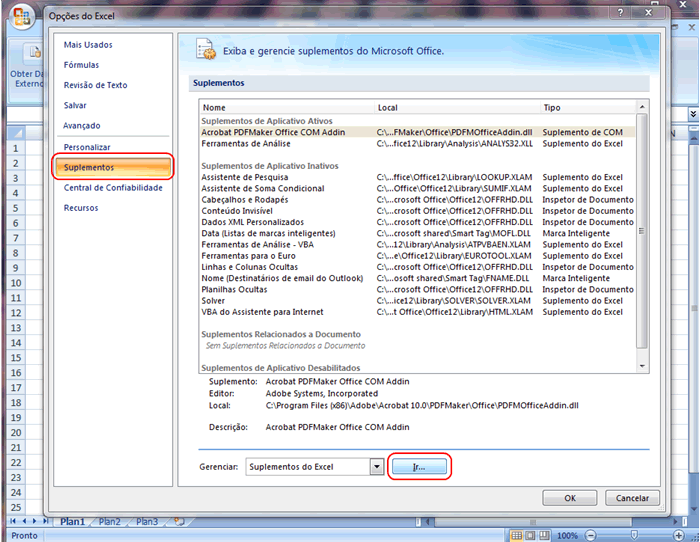
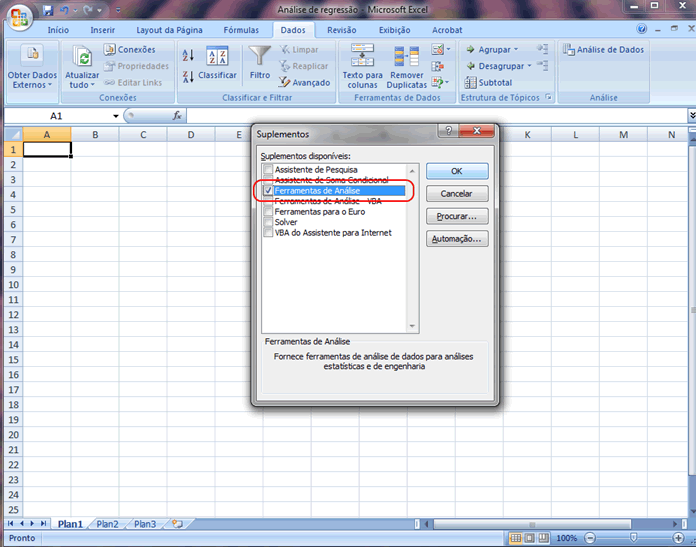
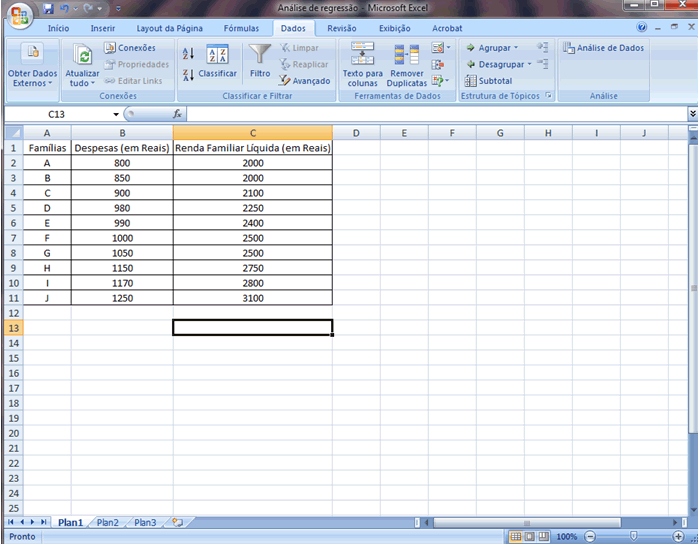
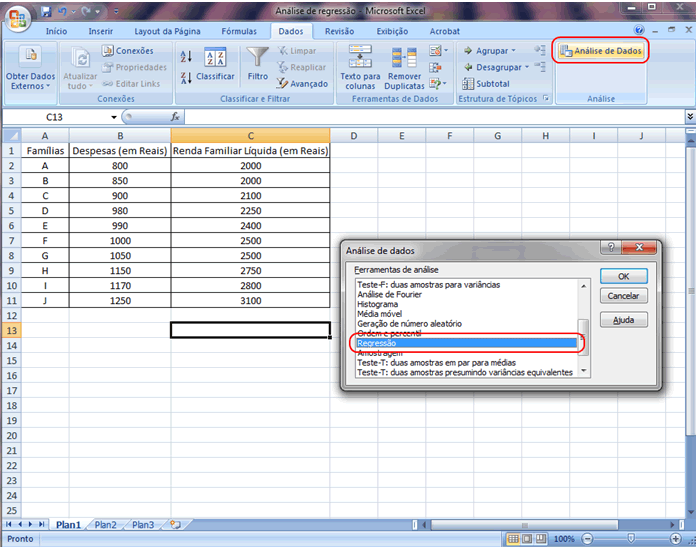
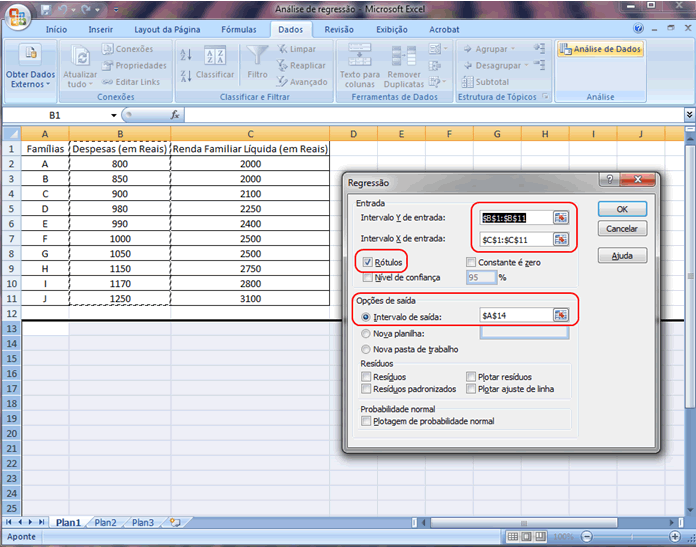
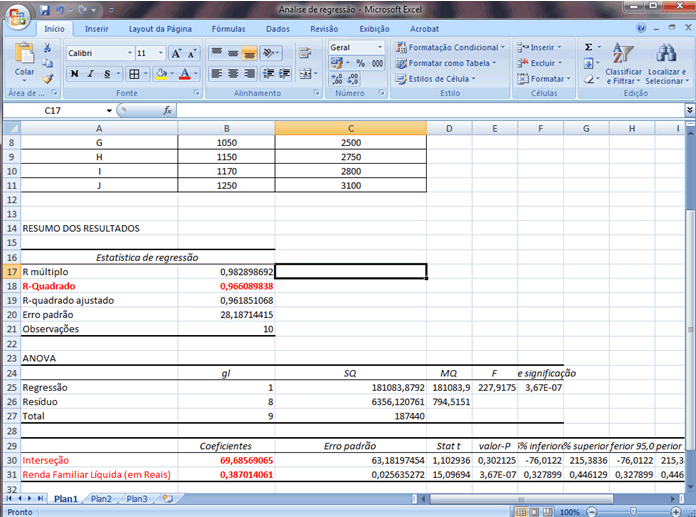
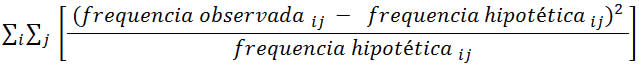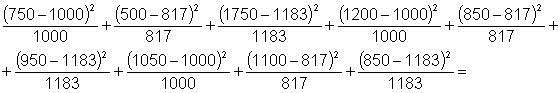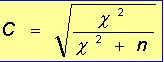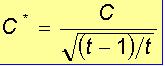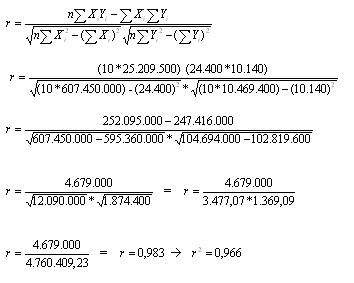1 - Caracterização da Análise Bidimensional
Nos estudos anteriores nossa análise recaiu sobre o comportamento de uma variável estudada de forma "individual", ou seja, não relacionada com outra(s).
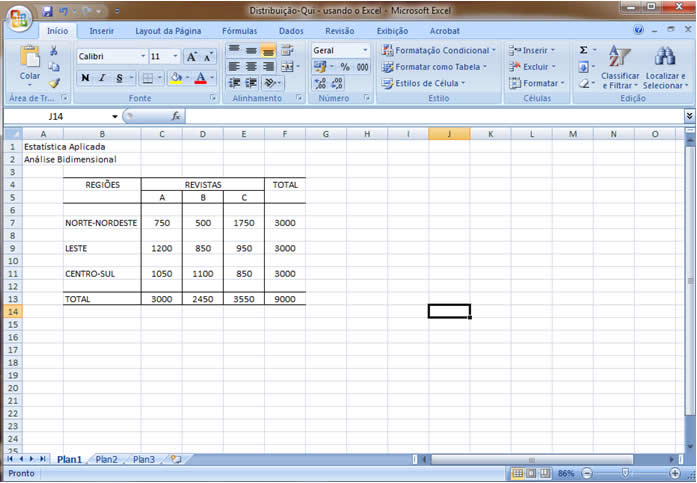
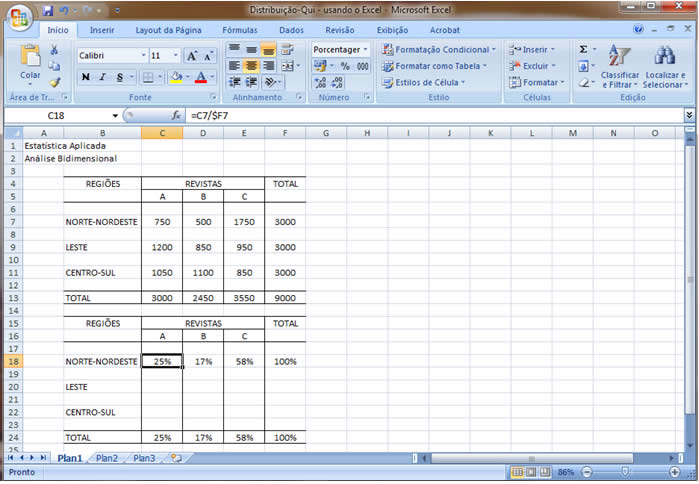
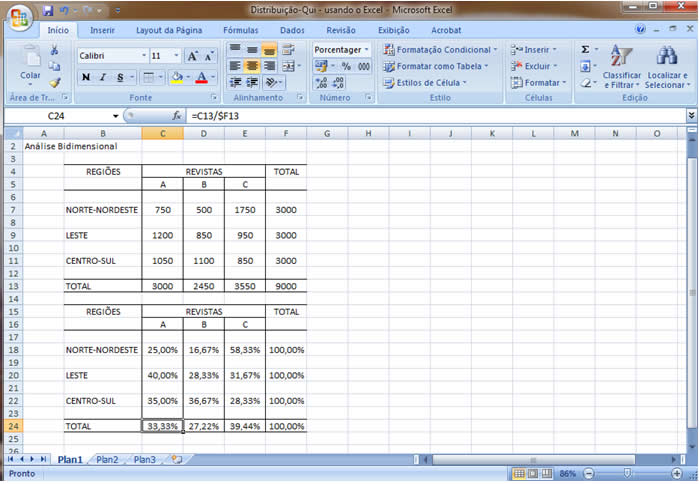
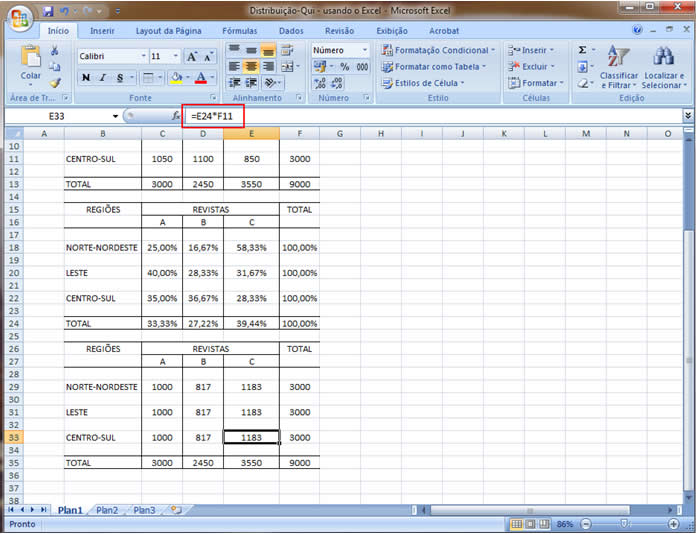
A partir de agora nossa atenção estará voltada para análise de duas variáveis observadas simultaneamente em um conjunto de indivíduos/objetos, de forma que os diferentes "níveis" das duas variáveis aparecerão cruzados/inter-relacionados, mostrando, efetivamente, um comportamento conjunto.
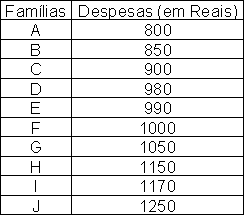
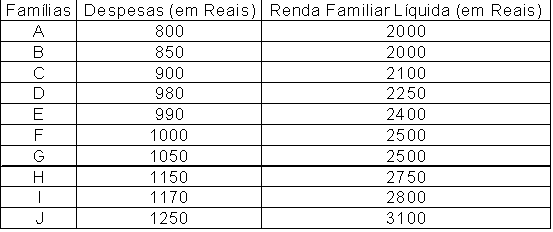
Existem dificuldades práticas para geração das medidas descritivas quando a variável não é tipicamente quantitativa. Essa técnica de análise permite que variáveis quantitativas e qualitativas (tanto ordinais como nominais) possam ser tratadas, em três diferentes combinações, como:
|